As I mentioned in my prior post about Spatial Video, the launch of the Apple Vision Pro has reignited interest in spatial and immersive video formats, and it’s exciting to hear from users who are experiencing this format for the first time. The release of my spatial video command-line tool and example spatial video player has inadvertently pulled me into a lot of fun discussions, and I’ve really enjoyed chatting with studios, content producers, camera manufacturers, streaming providers, enthusiasts, software developers, and even casual users. Many have shared test footage, and I’ve been impressed by a lot of what I’ve seen. In these interactions, I’m often asked about encoding options, playback, and streaming, and this post will focus on encoding.
To start, I’m not an Apple employee, and other than my time working at an immersive video startup (Pixvana, 2016-2020), I don’t have any secret or behind-the-scenes knowledge. Everything I’ve written here is based on my own research and experimentation. That means that some of this will be incorrect, and it’s likely that things will change, perhaps as early as WWDC24 in June (crossing my fingers). With that out of the way, let’s get going.
Encoding
Apple’s spatial and immersive videos are encoded using a multi-view extension of HEVC referred to as MV-HEVC (found in Annex G of the latest specification). While this format and extension were defined as a standard many years ago, as far as I can tell, MV-HEVC has not been used in practice. Because of this, there are very few encoders that support this format. As of this writing, these are the encoders that I’m aware of:
- spatial – my own command-line tool for encoding MV-HEVC on an Apple silicon Mac
- Spatialify – an iPhone/iPad app
- SpatialGen – an online encoding solution
- QooCam EGO spatial video and photo converter – for users of this Kandao camera
- Dolby/Hybrik – professional online encoding
- Ateme TITAN – professional encoding (note the upcoming April 16, 2024 panel discussion at NAB)
- SpatialMediaKit – an open source GitHub project for Mac
- MV-HEVC reference software – complex reference software mostly intended for conformance testing
Like my own spatial tool, many of these encoders rely on the MV-HEVC support that has been added to Apple’s AVFoundation framework. As such, you can expect them to behave in similar ways. I’m not as familiar with the professional solutions that are provided by Dolby/Hyrbik and Ateme, so I can’t say much about them. Finally, the MV-HEVC reference software was put together by the standards committee, and while it is an invaluable tool for testing conformance, it was never intended to be a commercial tool, and it is extremely slow. Also, the reference software was completed well before Apple defined its vexu metadata, so that would have to be added manually (my spatial tool can do this).
Layers
As I mentioned earlier, MV-HEVC is an extension to HEVC, and the multi-view nature of that extension is intended to encode multiple views of the same content all within a single bitstream. One use might be to enable multiple camera angles of an event – like a football game – to be carried in a single stream, perhaps allowing a user to switch between them. Another use might be to encode left- and right-eye views to be played back stereoscopically (in 3D).
To carry multiple views, MV-HEVC assigns each view a different layer ID. In a normal HEVC stream, there is only one so-called primary layer that is assigned an ID of 0. When you watch standard 2D HEVC-encoded media, you’re watching the only/primary layer 0 content. With Apple’s spatial and immersive MV-HEVC content, a second layer (typically ID 1) is also encoded, and it represents a second view of the same content. Note that while it’s common for layer 0 to represent a left-eye view, this is not a requirement.
One benefit of this scheme is that you can playback MV-HEVC content on a standard 2D player, and it will only playback the primary layer 0 content, effectively ignoring anything else. But, when played back on a MV-HEVC-aware player, each layered view can be presented to the appropriate eye. This is why my spatial tool allows you to choose which eye’s view is stored in the primary layer 0 for 2D-only players. Sometimes (like on iPhone 15 Pro), one camera’s view looks better than the other.
All video encoders take advantage of the fact that the current video frame looks an awful lot like the prior video frame. Which looks a lot like the one before that. Most of the bandwidth savings depends on this fact. This is called temporal (changes over time) or inter-view (where a view in this sense is just another image frame) compression. As an aside, if you’re more than casually interested in how this works, I highly recommend this excellent digital video introduction. But even if you don’t read that article, a lot of the data in compressed video consists of one frame referencing part of another frame (or frames) along with motion vectors that describe which direction and distance an image chunk has moved.
Now, what happens when we introduce the second layer (the other eye’s view) in MV-HEVC-encoded video? Well, in addition to a new set of frames that is tagged as layer 1, these layer 1 frames can also reference frames that are in layer 0. And because stereoscopic frames are remarkably similar – after all, the two captures are typically 65mm or less apart – there is a lot of efficiency when storing the layer 1 data: “looks almost exactly the same as layer 0, with these minor changes…” It isn’t unreasonable to expect 50% or more savings in that second layer.
This diagram shows a set of frames encoded in MV-HEVC. Perhaps confusing at first glance, the arrows show the flow of referenced image data. Notice that layer 0 does not depend on anything in layer 1, making this primary layer playable on standard 2D HEVC video players. Layer 1, however, relies on data from layer 0 and from other adjacent layer 1 frames.
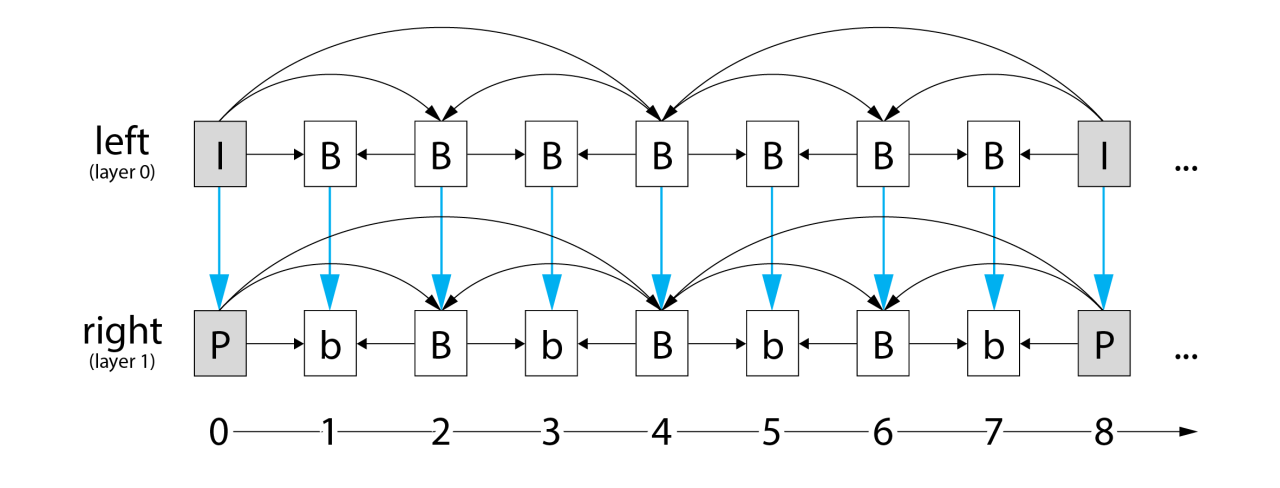
Thanks to Fraunhofer for the structure of this diagram.
Mystery
I am very familiar with MV-HEVC output that is recorded by Apple Vision Pro and iPhone 15 Pro, and it’s safe to assume that these are being encoded with AVFoundation. I’m also familiar with the output of my own spatial tool and a few of the others that I mentioned above, and they too use AVFoundation. However, the streams that Apple is using for its immersive content appear to be encoded by something else. Or at least a very different (future?) version of AVFoundation. Perhaps another WWDC24 announcement?
By monitoring the network, I’ve already learned that Apple’s immersive content is encoded in 10-bit HDR, 4320×4320 per-eye resolution, at 90 frames-per-second. Their best streaming version is around 50Mbps, and the format of the frame is (their version of) fisheye. While they’ve exposed a fisheye enumeration in Core Media and their files are tagged as such, they haven’t shared the details of this projection type. Because they’ve chosen it as the projection type for their excellent Apple TV immersive content, though, it’ll be interesting to hear more when they’re ready to share.
So, why do I suspect that they’re encoding their video with a different MV-HEVC tool? First, where I’d expect to see a FourCC codec type of hvc1 (as noted in the current Apple documentation), in some instances, I’ve also seen a qhvc codec type. I’ve never encountered that HEVC codec type, and as far as I know, AVFoundation currently tags all MV-HEVC content with hvc1. At least that’s been my experience. If anyone has more information about qhvc, drop me a line.
Next, as I explained in the prior section, the second layer in MV-HEVC-encoded files is expected to achieve a bitrate savings of around 50% or more by referencing the nearly-identical frame data in layer 0. But, when I compare files that have been encoded by Apple Vision Pro, iPhone 15 Pro, and the current version of AVFoundation (including my spatial tool), both layers are nearly identical in size. On the other hand, Apple’s immersive content is clearly using a more advanced encoder, and the second layer is only ~45% of the primary layer…just what you’d expect.
Here is a diagram that shows three subsections of three different MV-HEVC videos, each showing a layer 0 (blue), then layer 1 (green) cadence of frames. The height of each bar represents the size of that frame’s payload. Because the content of each video is different, this chart is only useful to illustrate the payload difference between layers.

As we’ve learned, for a mature encoder, we’d expect the green bars to be noticeably smaller than the blue bars. For Apple Vision Pro and spatial tool encodings (both using the current version of AVFoundation), the bars are often similar, and in some cases, the green bars are even higher than their blue counterparts. In contrast, look closely at the Apple Immersive data; the green layer 1 frame payload is always smaller.
Immaturity
What does this mean? Well, it means that Apple’s optimized 50Mbps stream might need closer to 70Mbps using the existing AVFoundation-based tools to achieve a similar quality. My guess is that the MV-HEVC encoder in AVFoundation is essentially encoding two separate HEVC streams, then “stitching” them together (by updating layer IDs and inter-frame references), almost as-if they’re completely independent of each other. That would explain the remarkable size similarity between the two layers, and as an initial release, this seems like a reasonable engineering simplification. It also aligns with Apple’s statement that one minute of spatial video from iPhone 15 Pro is approximately 130MB while one minute of regular video is 65MB…exactly half.
Another possibility is that it’s too computationally expensive to encode inter-layer references while capturing two live camera feeds in Vision Pro or iPhone 15 Pro. This makes a lot of sense, but I’d then expect a non-real-time source to produce a more efficient bitstream, and that’s not what I’m seeing.
For what it’s worth, I spent a bit of time trying to validate a lack of inter-layer references, but as mentioned, there are no readily-available tools that process MV-HEVC at this deeper level (even the reference decoder was having its issues). I started to modify some existing tools (and even wrote my own), but after a bunch of work, I was still too far away from an answer. So, I’ll leave it as a problem for another day.
To further improve compression efficiency, I tried to add AVFoundation’s multi-pass encoding to my spatial tool. Sadly, after many attempts and an unanswered post to the Apple Developer Forums, I haven’t had any luck. It appears that the current MV-HEVC encoder doesn’t support multi-pass encoding. Or if it does, I haven’t found the magical incantation to get it working properly.
Finally, I tried adding more data rate options to my spatial tool. The tool can currently target a quality level or an average bitrate, but it really needs finer control for better HLS streaming support. Unfortunately, I couldn’t get the data rate limits feature to work either. Again, I’m either doing something wrong, or the current encoder doesn’t yet support all of these features.
Closing Thoughts
I’ve been exploring MV-HEVC in depth since the beginning of the year. I continue to think that it’s a great format for immersive media, but it’s clear that the current state of encoders (at least those that I’ve encountered) are in their infancy. Because the multi-view extensions for HEVC have never really been used in the past, HEVC encoders have reached a mature state without multi-view support. It will now take some effort to revisit these codebases to add support for things like multiple input streams, the introduction of additional layers, and features like rate control.
While we wait for answers at WWDC24, we’re in an awkward transition period where the tools we have to encode media will require higher bitrates and offer less control over bitstreams. We can encode rectilinear media for playback in the Files and Photos apps on Vision Pro, but Apple has provided no native player support for these more immersive formats (though you can use my example spatial player). Fortunately, Apple’s HLS toolset has been updated to handle spatial and immersive media. I had intended to write about streaming MV-HEVC in this post, but it’s already long enough, so I’ll save that topic for another time.
As always, I hope this information is useful, and if you have any comments, feedback, suggestions, or if you just want to share some media, feel free to contact me.
Leave a Reply